Tanuki-8B
8億パラメータのベースモデル。コンパクトながら高性能な日本語LLMとして、 10B級モデルを上回る対話性能を実現。推論速度と性能のバランスに優れた実用的なモデルです。
8Bパラメータ
最高性能
ページ訪問者数



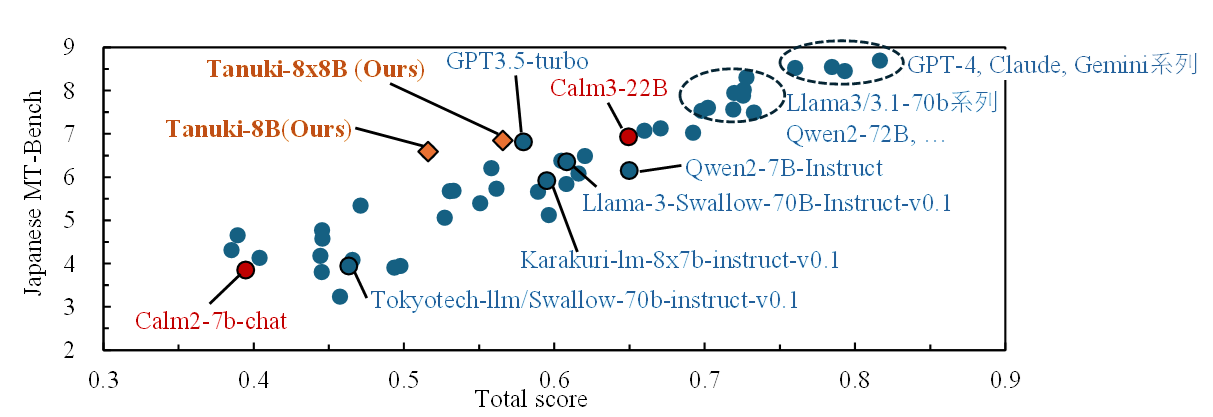
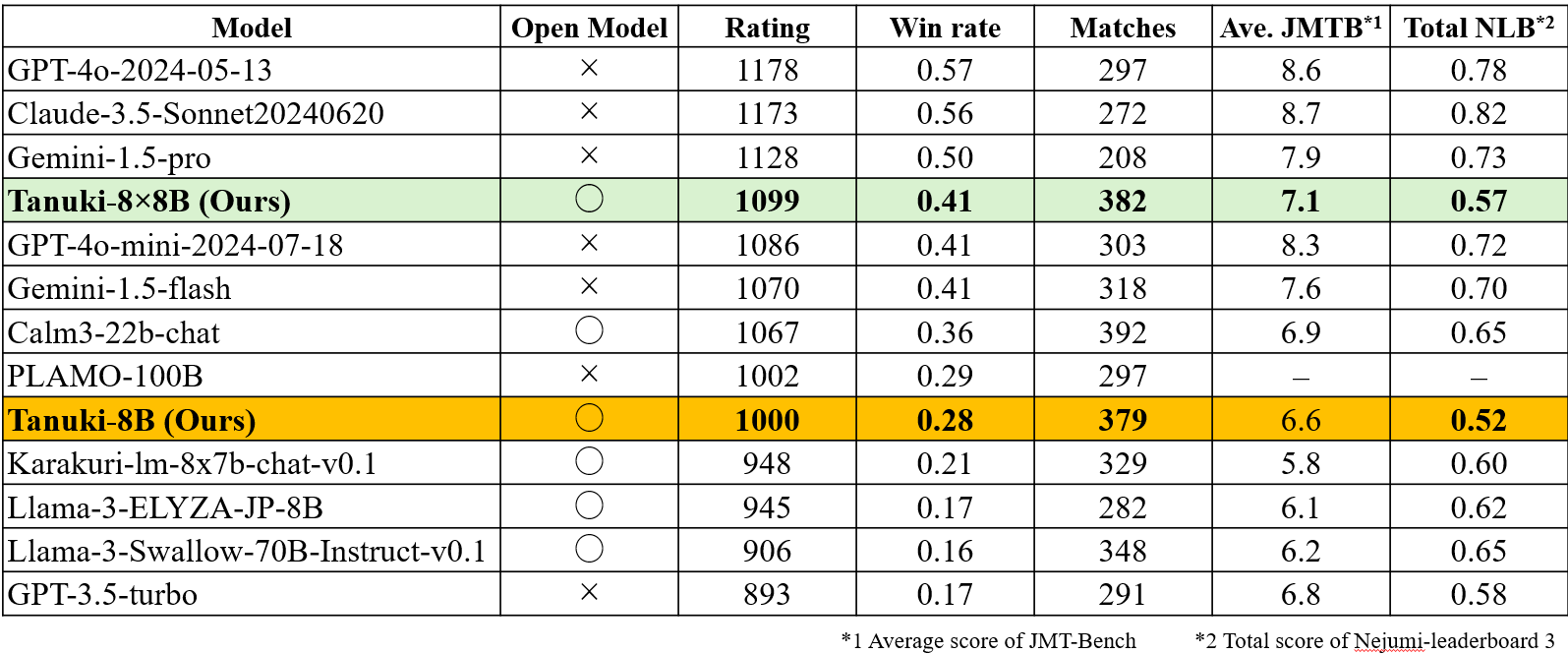
Tanuki LLM(タヌキ大規模言語モデル)は、公募型の貢献者コミュニティによって開発された日本語特化の大規模言語モデル(Large Language Model)です。 Tanuki-8BおよびTanuki-8×8Bの2つのモデルを開発し、 Japanese MT-Bench (JMT-Bench)において、Tanuki-8Bは10B級モデルを上回る性能を示し、 Tanuki-8×8Bは国内でフルスクラッチ開発されたモデルとしてトップレベルの性能を達成しました(2024年8月末時点)。
本プロジェクトでは、オープンソースとして学習コードや使用方法の解説動画・記事を公開し、 日本語での対話・作文性能に特化したLLMの研究開発を推進しています。
松尾研LLMコンペ2025の開発メンバーを募集中です。概要や応募方法についてご案内した説明会のアーカイブ動画および資料を公開しています。 たくさんのご応募をお待ちしております!
8億パラメータのベースモデル。コンパクトながら高性能な日本語LLMとして、 10B級モデルを上回る対話性能を実現。推論速度と性能のバランスに優れた実用的なモデルです。
MoE(Mixture of Experts)アーキテクチャを採用した高性能モデル。 アップサイクリング手法により効率的に開発され、国内最高レベルの日本語LLM性能を達成しています。
合成データを継続事前学習・事後学習に用いることで、LLM の対話能力が向上することを実証しました。
アップサイクリングにより、学習途中の Tanuki-8B をベースに MoE 形式の Tanuki-8×8B を構築し、 計算コストと学習失敗リスクを低減しました。国内初のアップサイクリング成功例です。
安全性評価は今後の課題です。
アブレーション研究により要因別の精度寄与を明らかにする必要があります。
日本語・英語特化のため、他言語対応は限定的です。